
Our previous blogs explored how optical interconnects are enabling the AI networking infrastructure to scale, both from the training as well as the inference perspective. As these blogs highlighted, training models are expected to outgrow a single physical data center in terms of space and power, which would lead to distributed training across multiple sites, known as scale-across networking.
In this blog, we’ll review how the AI network infrastructure is evolving and dive deeper into how optical interconnects play a crucial part in this network inside and outside the data center.
Models are Getting Larger!
When reviewing the various AI training models and how they’ve been progressing, it’s no surprise that the models and their associated training cluster sizes are getting larger and larger over time. AI clusters continue to quickly evolve: the number of model parameters are increasing, the operating points are changing, and the number of GPUs is increasing with every generation. Over the last approximately six years, there’s been massive growth in parameters, FLOPS (Floating Point Operations Per Second), and GPUs, and it’s all condensed into a metric of MMLU (see inset), which serves as a proxy for knowledge and reasoning.
The AI training cluster size is proportional to perceived capabilities of intelligence (MMLU), and the drive to increase these capabilities is what is currently driving the AI infrastructure industry. With focus turning to increasing reasoning abilities, this is driving an increase in an AI cluster’s scale both inside and now extending outside a single AI data center.
For AI clusters within a data center, there are two basic networks. The front-end network is essentially what is today’s cloud network, and it is comprised of leaf and spine architectures, with many individual servers in racks. The back-end network refers to the AI infrastructure itself. This back-end network inside the data center can be further segmented into the scale-up and scale-out networks whose goals are to aggregate many compute entities into a single AI cluster.
The scale-up network is essentially a connection of many xPUs tightly coupled to each other so they’re acting as an optimized and efficient compute device. The goal is to create the largest aggregate xPU so that the network has the ability to process larger AI workloads. Within this scale-up network, there are key parameters to pay attention to. First, there is a high density of xPU-to-xPU interconnects that are primarily copper based today. From an interconnect point of view, the radix is extremely wide because the goal is to have every xPU talking to every xPU through all these switches. By optimizing this scale-up network, all the xPUs are essentially acting as one compute device.
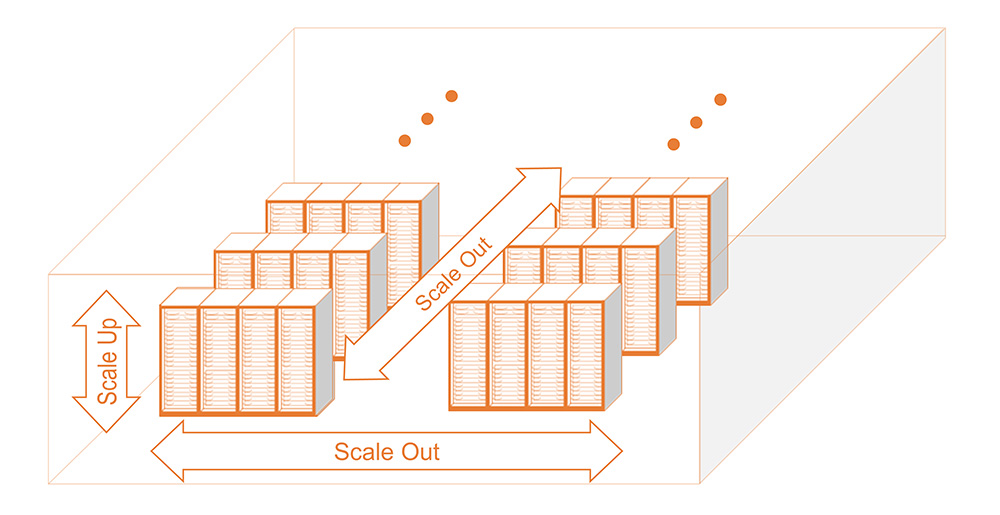 Figure 1. AI back-end network inside the data center comprised of scale-up and scale-out architectures.
Figure 1. AI back-end network inside the data center comprised of scale-up and scale-out architectures.
But it doesn’t stop there. These scale-up nodes (i.e., racks) can be connected together to become a scale-out network that uses a further series of switches in a classic Clos network architecture (fabric, leaf, and spine connecting together). In the case of scale-out interconnects, bigger, fatter pipes are the goal, while radix isn’t as critical. The aggregate of the scale-up and the scale-out network is how you build these AI clusters inside the data center.
In a nutshell, scale-up networks focus on connecting as many xPUs as possible for parallel processing. Scale-out networks then connect these scale-up nodes together, demanding high-speed, wide-radix interconnects. The combination of scale-up and scale-out is essential for building next-generation AI infrastructures.
Power Constraints and the Rise of Scale-Across Networking
At some point, building these scale-out networks will outgrow the physical size or electrical power capacity of a single data center. As AI clusters grow, power consumption becomes a dominant concern. The shift from 640 Gbps switches 15 years ago to a projection towards future 400 Tbps switches will result in a bandwidth increase by 640x, while power requirements could grow by 119x. While core digital and interconnect efficiencies (thanks to Moore’s Law) help, the sheer amount of bandwidth drives up the total power.
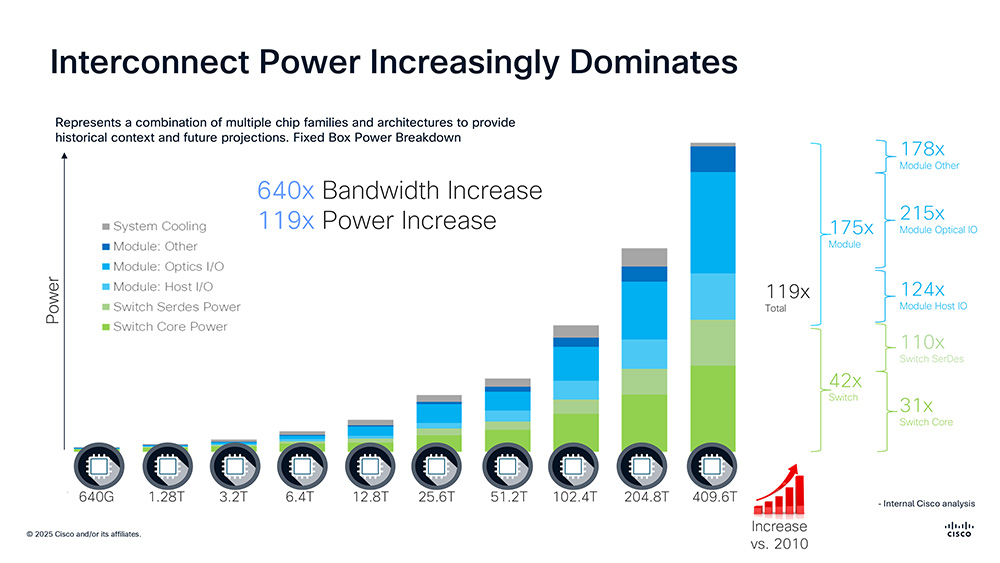 Figure 2. Analysis of how power consumption increases as switch capacity increases.
Figure 2. Analysis of how power consumption increases as switch capacity increases.
Major data center operators are now confronting the physical, operational, commercial, and regulatory challenges of power delivery and cooling to these sites. The world’s largest clusters are already operating in facilities designed to scale to gigawatts of electricity—comparable to small cities. This has forced a rethinking in data center location strategy, with operators seeking regions offering lower-cost and more-reliable power.
The quest to achieve higher intelligence is therefore also being limited by these constraints. To alleviate these constraints, models have been created to essentially mimic GPU to GPU scale-out interconnects, but expanded outside a single data center facility (to campus, metro, and even beyond). This is referred to as the scale-across network—connecting a back-end network across multiple data centers in close proximity or across regions.
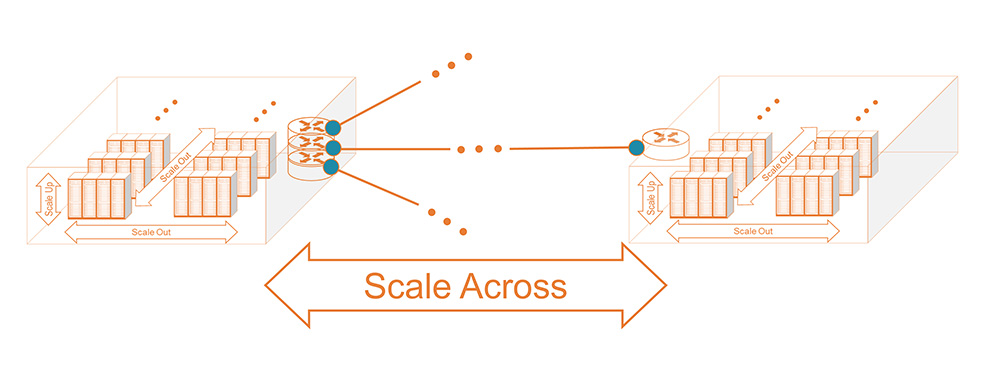 Figure 3. Scale Across architecture extends the AI Back-End network beyond the physical data center.
Figure 3. Scale Across architecture extends the AI Back-End network beyond the physical data center.
Isn’t Scale-Across Bad for Latency?
A scale-across network architecture requires not only robust interconnects, but also careful management of network latency and congestion. Latency can be a concern for some AI operations (notably inference). AI workloads are highly synchronized meaning that transmission latencies from longer fiber distances can be accounted for in the synchronized workload, even if the scale-across interconnect is tens to hundreds of kilometers in length. Therefore, latency itself for scale-across interconnects is not a fundamental issue if the traffic patterns are well understood and controlled.
Tail latency (the impact of outlier delays within the synchronized workload) is what needs to be minimized. This is when one aspect of the workload is delayed for one of many reasons. When this happens, the whole workload is halted, waiting for that data to come in. It is tail latency that really impacts the job completion time and affects the efficiency and productivity of AI workloads. The great concern here is around job completion time and what affects it. That is why it’s important to minimize the impact of network effects, such as load balancing and congestion control. Proactive and reactive congestion control, alongside deep buffering, become critical tools in maintaining performance across scale-across geographically distributed clusters.
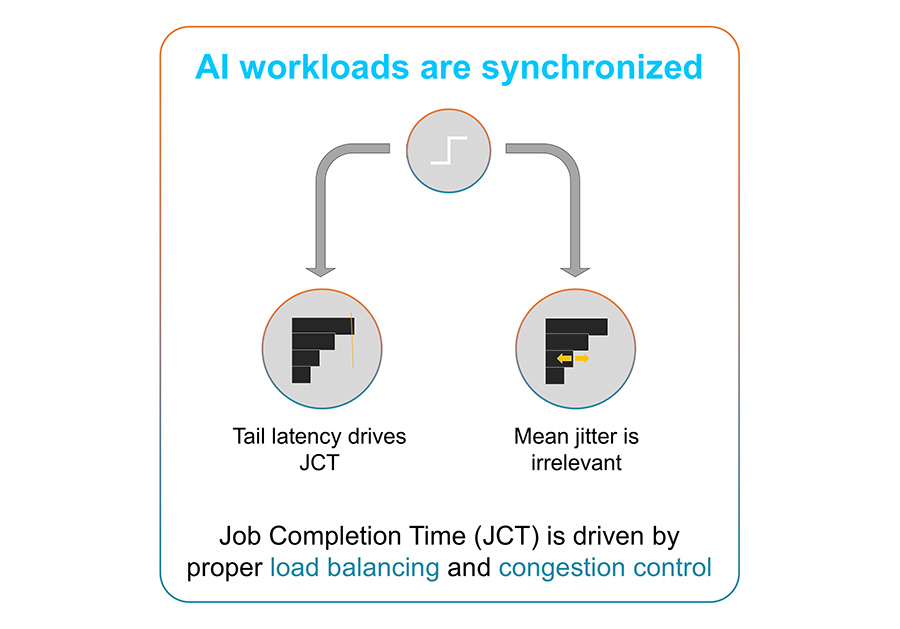 Figure 4. Tail latency is the culprit that can negatively affect workload completion.
Figure 4. Tail latency is the culprit that can negatively affect workload completion.
Innovations in Optical Interconnects
Optical interconnects in a scale-across network are made possible today by coherent technology which includes both pluggable coherent optics as well as performance-optimized embedded solutions. However, AI’s bandwidth demands are transforming the optical interconnect landscape. The lessons from cloud networking over the past decade—such as the adoption of DCI (Data Center Interconnect) and leaf/spine topologies—are being extended and accelerated by AI.
Pluggable coherent optics have emerged as a key enabler, reducing power consumption by eliminating unnecessary client interfaces and allowing direct router-to-router connectivity. The evolution from early (~120km reach) ZR modules for metro DCI to ZR+ and ULH (ultra-long haul, 1000+ km) now provides flexible, scalable solutions for both intra- and inter-data center links.
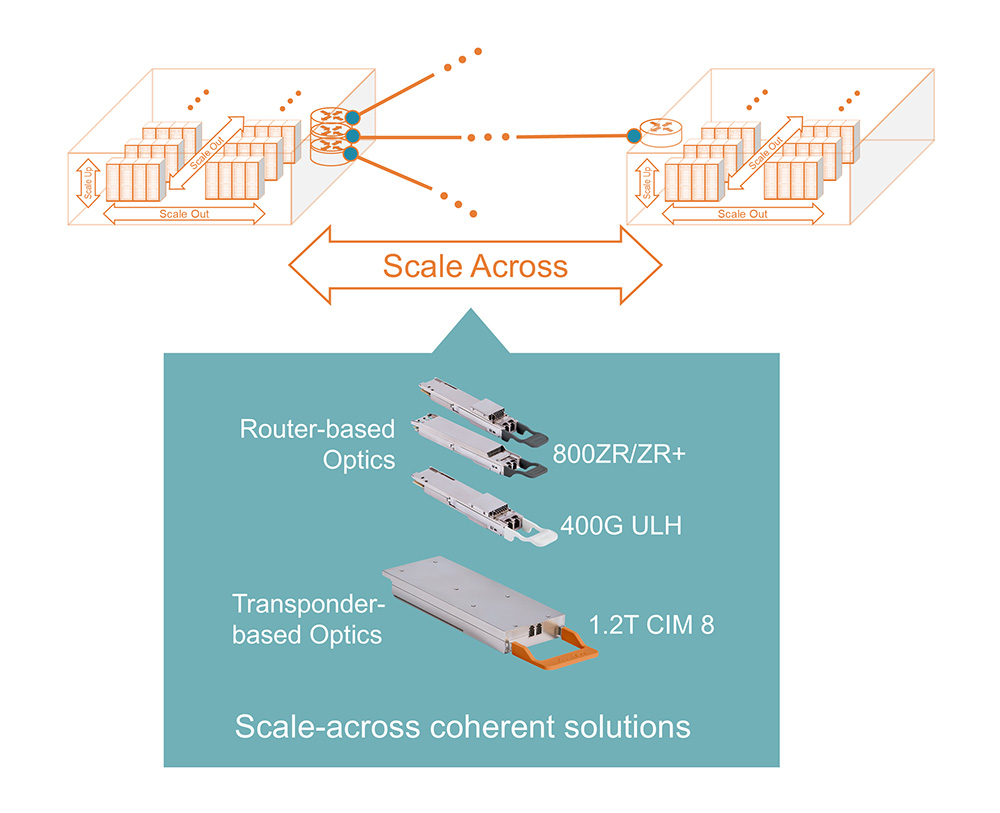 Figure 5. Coherent optics play a key role in scale-across networks.
Figure 5. Coherent optics play a key role in scale-across networks.
Analyst forecasts predict tremendous growth for AI, with 800ZR+ and later 1600ZR+ modules becoming the workhorses of scale-across architectures. It should be noted that the capacity needed for these scale-across networks is separate from the capacity required for the traditional front-end DCI needs. Traditional coherent optics solutions utilize the C-band spectrum of the low-loss optical fiber transmission window. However, these tremendous capacity requirements for AI scale across infrastructure are accelerating coherent optics adoption of the secondary low-loss transmission window, the L-band spectrum.
Design Trade-Offs and Industry Collaboration
As architectures evolve, so do the trade-offs between simplicity, flexibility, power, and reliability. Disaggregation—the ability to mix and match components from different vendors—offers operational agility and resilience. Flatter, simpler line systems and large capacity pipes are preferred to minimize complexity and maximize scalability.
Interoperability, power efficiency, and reliability are all top-of-mind, especially as network operators tackle new challenges such as regenerator site management and multi-site synchronization. Uptime is paramount because any disruption can create tail latency that results in a costly halt to a training workload.
Looking Ahead: Scaling the Next Generation of AI Infrastructure
The industry is still in the early days of deploying AI scale-across architectures, but the trajectory is clear. Class 3 baud rate technologies (such as 800ZR/ZR+ and advanced transponders) will dominate near-term deployments, while Class 4 and higher baud rate technologies will see even more aggressive innovation.
AI is acting as a powerful forcing function on the industry to find solutions to the scaling challenge. Every technology area is being pushed to its limits, and there’s no single solution to the scale challenge. As the market continues to evolve, success will depend on collaboration, ecosystem maturity, and the ability to balance trade-offs for maximum performance and cost-efficiency. This future will be shaped by the collective efforts of manufacturers, operators, and innovators across the industry. As with the rise of cloud networking a decade ago, those who adapt quickly and work together will shape the next generation of digital infrastructure.
Reference: “AI Infrastructure at Scale” Lightwave Webinar, https://www.lightwaveonline.com/resources/webinar/55328687/ai-infrastructure-at-scale

